
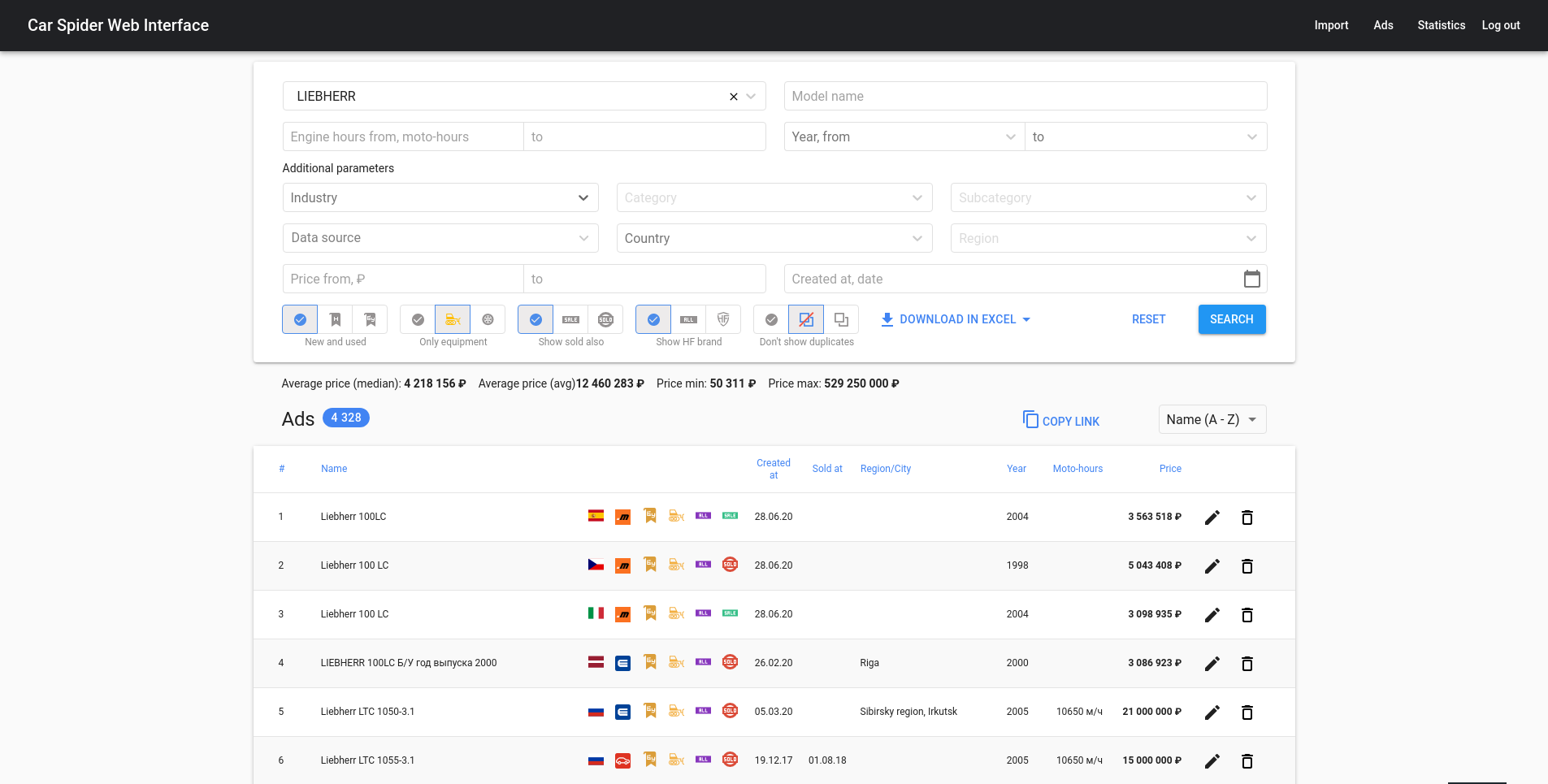
Project for a company which sells construction equipment and heavy machinery. They want to know prices and some statistics.
So we needed to regularly parse 10 websites selling equipment. Some of them are pretty big so you can't just parse them from one ip address (they will ban you for frequent requests).
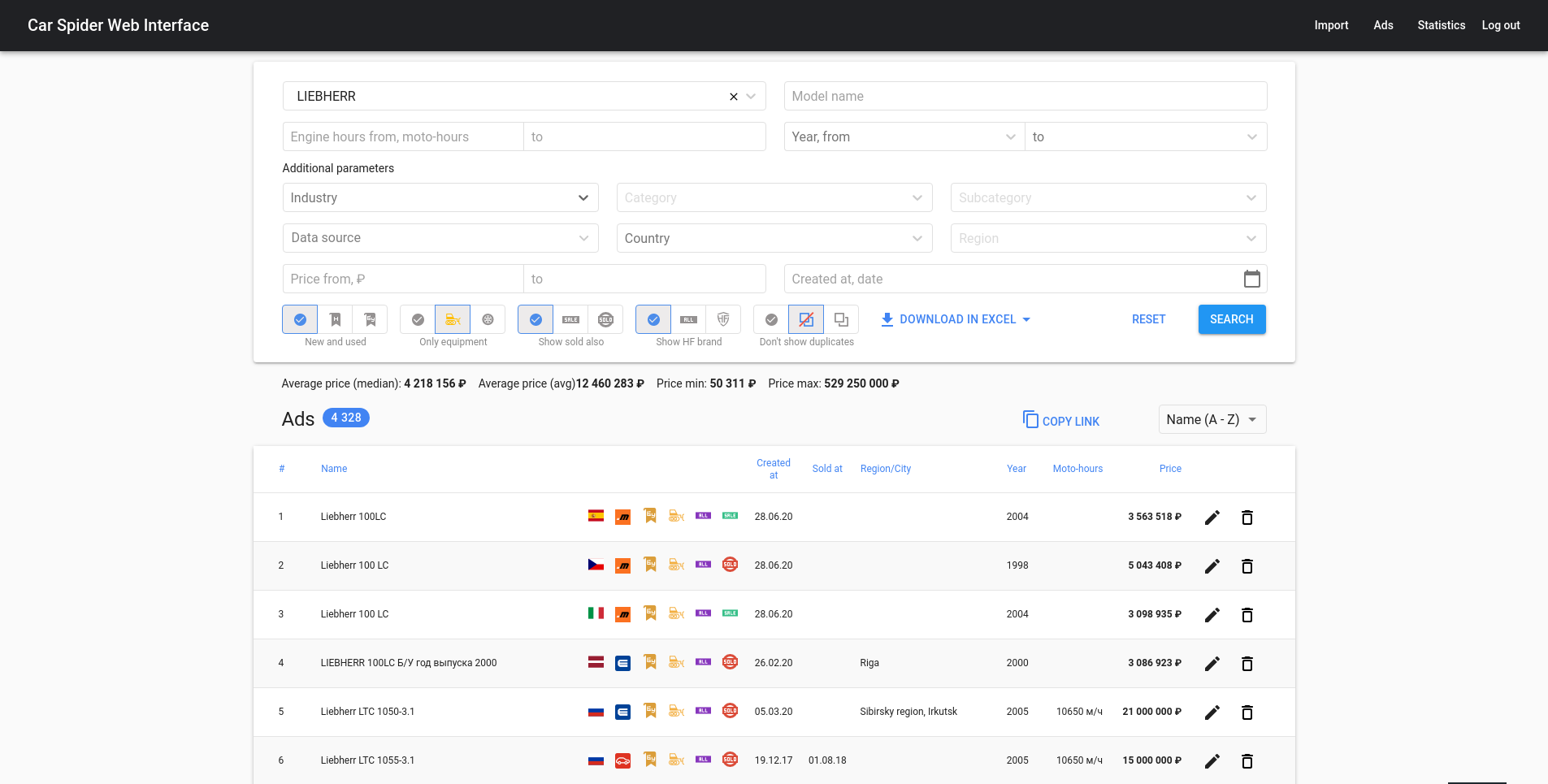
Some features of this project
- Grabbing and parsing data about proxy servers (Buying bunch of private proxies is not cheap, and client didn't have approved budget for that so we used open proxies).
The problem with open proxies (with private too by the way) that they can be already banned on the websites you need to parse. You need to make checks for that. Sometimes proxy just die and you need to catch that too. Some websites are banning access from different countries. So you can use only specific proxies. And you will know this details only then you are actually implementing a parser for a specific website. What's why it is so hard to tell the estimate time for writing a parser.
So I wrote a lot of code to orchestrate proxy lists, check for proxy health, check its answers, etc...
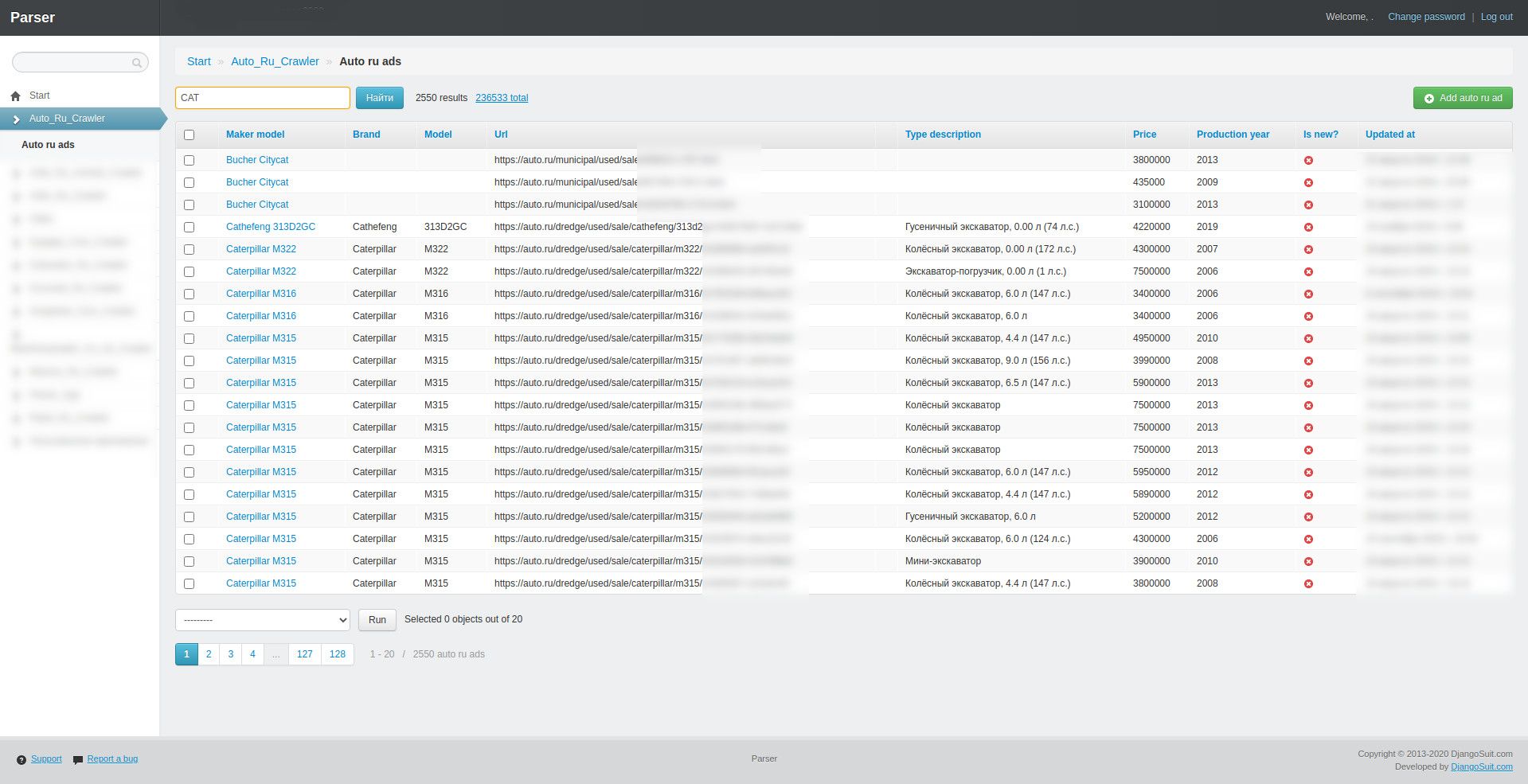
- Parsing bunch of websites with an construction equipment.
Each website is unique in some way. You have to be gentle and not send a lot of requests and you need to mimic regular user as much as possible. And you can't just parse 100% of every website every time so you need to think of a way to select only updated information.
Interesting example: you enter bulldozers page of a website. it says it has 100 pages, 10 ads each. You can walk between pages adding &page= to the URL. Sweet. But if you are not careful you will not notice that after page 50 they just gave you the page № 1 content. So there is 100 x 10 = 1000 ads but you can only get 500 ads. And actually you need to split this ads into smallest chunks - no more 50 pages in results. So I used different filters on a website like year of manufacture, brand name, etc... It's just one of funny examples of problems with parsing websites.
- Working around CAPTCHAs and bans. There are services to help you with captcha, or sometimes you can just switch to another proxy.
- Extracting and processing data - (search for duplicates, calculating price stats, export to excel)
- GraphQL API for frontend
I wrote proxy orchestrating part, web-crawler and 8 of 10 website parsers.
Used technologies:
Backend: python, django, django-rest-framework, celery, graphql, postrgresql, redis, lxml, requests, beautifulsoup, openpyxl
Frontend: react, graphql